Hashmap internal working
Hashmap works on the principle of Hashing. Hashing works on the three terms : Hash Function, Hash value and Bucket. Now we will go through each of them one by one.
Hash Function : Hash Function in hashing is the function which converts an Object into integer form. In Java hashcode() method does this work.
Hash Value : Hash Value in java is the integer value returned by the Hash Function by converting memory address into Integer to find the index in bucket.
Bucket : Bucket is used to store key value pairs. Bucket can store multiple key value pair. In hashmap bucket use linked list to store objects.
As we have understand the Hash Function , Hash Value and Bucket concepts in Hashing. Now we will see what is hashCode() method in Java API and How does it gives integer value of memory address.
hashCode()
hashCode() method is used to get the hash Code of an object. hashCode() method of object class returns the memory reference of object in integer form. Definition of hashCode() method is as
As per above definition we can see that hashCode method is native method which means that the method is not implemented in the code that runs on JVM. Native method are usually written in C or C++. Native method are usually used to interface with system calls and other libraries written in other programming language.
Why hashcode() method is native method ?
hashcode() has been made native because of the performance issue. hashcode() is written in c language which is more near to machine code.Hence it make the process fast to generate integer value from memory address using native method.
Is there any difference in the given hashcode() method or the one we override and write in java ?
No both gives the integer value by converting memory address.Difference is just that native method is faster than overriden method.
How get() method works in Hashmap ?
In HashMap, when you try to get the object using get(key) method, the HashMap first gets the hash code of the key (remember that key is an object in the HashMap and it should have hashCode() method overridden) and generates again the hashcode to just defend against poor quality hash functions. Using this hashcode, an index for hash code will be created and this index is used to look up the entry table which is where all the hash entries are available. Now, once you get the Entry object from the Entry table using index, check if the key of the Entry object is same as the key we sent as parameter to get method. If yes, then return the value of the Entry object. If no, then go to next Entry object and continue the same.
Below is the definition of get() method :
static hash() method definition in Hashmap
From the above definition , we can see that get method call the hashCode() twice to defend against the poor quality of hashCode() method.
How come calling the hashcode() defend against the poor quality of hashcode() ?
Comments for static hashcode() in hashmap says that :
"Applies a supplemental hash function to a given hashCode, which defends against poor quality hash functions. This is critical because HashMap uses power-of-two length hash tables, that otherwise encounter collisions for hashCodes that do not differ in lower bits. What do this means???"
It means that if in case the algorithm we wrote for hashcode generation does not distribute/mix lower bits evenly, it will lead to more collisions. For example, we have hashcode logic of “empId*deptId” and if deptId is even, it would always generate even hashcodes because any number multiplied by EVEN is always EVEN.
If we directly depend on these hashcodes to compute the index and store our objects into hashmap then
1. Odd places in the hashmap are always empty
2. Because of 1 reason, it would leave us to use only even places and hence double the number of collisions
How put() method works in Hashmap ?
Below is the definition of put() method :
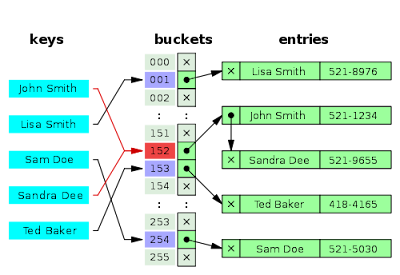
As per the definition of put method , we can find that it first find the hascode of key and again regenerate the hashcode to prevent collision , then it find the index of the key using regenerated hashcode. If key exists then it will override the old value otherwise it will create the new entry in the table. See the below picture for clarification :
What happens if two key have same hashcode ?
If two key give same hashcode, then equals method come in to the action. Then both the keys are matched using the equals of they are exactly equal or just their hascode is same. If both the keys are same then the old value is replaced with the new value. If both the keys are not equal then the new key is added in the same bucket as that of existing key.
When collision happens in hashmap?
hahscode() method can give same hash vale for two different key in that case collision happens.
How do you retrieve value object when two keys with same hashcode are stored in hashmap?
Using hashcode wo go to the right bucket and using equals we find the right element in the bucket and then return it.
How does 2 different keys with same hashcode are stored in hashmap?
Usual answer is in bucket but technically they are all stored in a single linked list. Little difference is that insertion of new element to the linked list is made at the head instead of tail to avoid tail traversal.
What is bucket and what can be maximum number of buckets in hashmap?
A bucket is an instance of the linked list (Entry Inner Class in my previous post) and we can have as many number of buckets as length of the hashmap at maximum, for example, in a hashmap of length 8, there can be maximum of 8 buckets, each is an instance of linked list.
If you have any questions or you want to add anything in the above , please comment below.
Hash Function : Hash Function in hashing is the function which converts an Object into integer form. In Java hashcode() method does this work.
Hash Value : Hash Value in java is the integer value returned by the Hash Function by converting memory address into Integer to find the index in bucket.
Bucket : Bucket is used to store key value pairs. Bucket can store multiple key value pair. In hashmap bucket use linked list to store objects.
As we have understand the Hash Function , Hash Value and Bucket concepts in Hashing. Now we will see what is hashCode() method in Java API and How does it gives integer value of memory address.
hashCode()
hashCode() method is used to get the hash Code of an object. hashCode() method of object class returns the memory reference of object in integer form. Definition of hashCode() method is as
public native int hashCode();
As per above definition we can see that hashCode method is native method which means that the method is not implemented in the code that runs on JVM. Native method are usually written in C or C++. Native method are usually used to interface with system calls and other libraries written in other programming language.
Why hashcode() method is native method ?
hashcode() has been made native because of the performance issue. hashcode() is written in c language which is more near to machine code.Hence it make the process fast to generate integer value from memory address using native method.
Is there any difference in the given hashcode() method or the one we override and write in java ?
No both gives the integer value by converting memory address.Difference is just that native method is faster than overriden method.
How get() method works in Hashmap ?
In HashMap, when you try to get the object using get(key) method, the HashMap first gets the hash code of the key (remember that key is an object in the HashMap and it should have hashCode() method overridden) and generates again the hashcode to just defend against poor quality hash functions. Using this hashcode, an index for hash code will be created and this index is used to look up the entry table which is where all the hash entries are available. Now, once you get the Entry object from the Entry table using index, check if the key of the Entry object is same as the key we sent as parameter to get method. If yes, then return the value of the Entry object. If no, then go to next Entry object and continue the same.
Below is the definition of get() method :
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
*
A return value of {@code null} does not necessarily
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
static hash() method definition in Hashmap
/**
* Applies a supplemental hash function to a given hashCode, which
* defends against poor quality hash functions. This is critical
* because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
From the above definition , we can see that get method call the hashCode() twice to defend against the poor quality of hashCode() method.
How come calling the hashcode() defend against the poor quality of hashcode() ?
Comments for static hashcode() in hashmap says that :
"Applies a supplemental hash function to a given hashCode, which defends against poor quality hash functions. This is critical because HashMap uses power-of-two length hash tables, that otherwise encounter collisions for hashCodes that do not differ in lower bits. What do this means???"
It means that if in case the algorithm we wrote for hashcode generation does not distribute/mix lower bits evenly, it will lead to more collisions. For example, we have hashcode logic of “empId*deptId” and if deptId is even, it would always generate even hashcodes because any number multiplied by EVEN is always EVEN.
If we directly depend on these hashcodes to compute the index and store our objects into hashmap then
1. Odd places in the hashmap are always empty
2. Because of 1 reason, it would leave us to use only even places and hence double the number of collisions
How put() method works in Hashmap ?
Below is the definition of put() method :
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
As per the definition of put method , we can find that it first find the hascode of key and again regenerate the hashcode to prevent collision , then it find the index of the key using regenerated hashcode. If key exists then it will override the old value otherwise it will create the new entry in the table. See the below picture for clarification :

What happens if two key have same hashcode ?
If two key give same hashcode, then equals method come in to the action. Then both the keys are matched using the equals of they are exactly equal or just their hascode is same. If both the keys are same then the old value is replaced with the new value. If both the keys are not equal then the new key is added in the same bucket as that of existing key.
When collision happens in hashmap?
hahscode() method can give same hash vale for two different key in that case collision happens.
How do you retrieve value object when two keys with same hashcode are stored in hashmap?
Using hashcode wo go to the right bucket and using equals we find the right element in the bucket and then return it.
How does 2 different keys with same hashcode are stored in hashmap?
Usual answer is in bucket but technically they are all stored in a single linked list. Little difference is that insertion of new element to the linked list is made at the head instead of tail to avoid tail traversal.
What is bucket and what can be maximum number of buckets in hashmap?
A bucket is an instance of the linked list (Entry Inner Class in my previous post) and we can have as many number of buckets as length of the hashmap at maximum, for example, in a hashmap of length 8, there can be maximum of 8 buckets, each is an instance of linked list.
If you have any questions or you want to add anything in the above , please comment below.


Comments
Post a Comment